Operational procedures
This section describes common operations to be performed on operational clusters.
Reboot procedures
The general procedure to reboot a service is as follows:
Check the health of the service. (If the health isn’t good search for “troubleshooting” in the documentation. If it is good, move to the next step.)
Reboot the server the service is running on.
Check the health of the service again. (If the health isn’t good search for “troubleshooting” in the documentation. If it is good, your reboot was succesful.)
The method for checking health is different for each service type, you can find a list of those methods here.
The method to reset a service is the same for most services, except for restund, for which the procedure is different, and can be found here.
For other (non-restund) services, the procedure is as follows:
Assuming in this example you are trying to reboot a minio server, follow these steps:
First, check the health of the services.
Second, reboot the services:
ssh -t <ip of minio node> sudo reboot
Third, wait until the service is up again by trying to connect to it via SSH :
ssh -o 'ConnectionAttempts 3600' <ip of minio node> exit
(ConnectionAttempts will make it so it attempts to connect until the host is actually Up and the connection is succesful)
Fourth, check the health of the service again.
Health checks
This is a list of the health-checking procedures currently documented, for different service types:
Restund (the health check is explained as part of the reboot procedure).
To check the health of different services not listed here, see the documentation for that specific project, or ask your Wire contact.
Note
If a service is running inside a Kubernetes pod, checking its health is easy: if the pod is running, it is healthy. A non-healthy pod will stop running, and will be shown as such.
Draining pods from a node for maintainance
You might want to remove («drain») all pods from a specific node/server, so you can do maintainance work on it, without disrupting the entire cluster.
If you want to do this, you should follow the procudure found at: https://kubernetes.io/docs/tasks/administer-cluster/safely-drain-node/
In short, the procedure is essentially:
First, identify the name of the node you wish to drain. You can list all of the nodes in your cluster with
kubectl get nodes
Next, tell Kubernetes to drain the node:
kubectl drain <node name>
Once it returns (without giving an error), you can power down the node (or equivalently, if on a cloud platform, delete the virtual machine backing the node). If you leave the node in the cluster during the maintenance operation, you need to run
kubectl uncordon <node name>
afterwards to tell Kubernetes that it can resume scheduling new pods onto the node.
Understand release tags
We have two major release tags that you sometimes want to map on each other: github, and helm chart.
Github have a tag of the form vYYYY-MM-DD, and the release notes and (some build artefacts) can be found on github, eg., here. Helm chart tags have the form N.NNN.0. The minor version 0 is for the development branch; non-zero values refer to unreleased intermediate states.
On the command line
You can find the github tag for a helm chart tag like this:
git tag --points-at v2022-01-18 | sort
… and the other way around like this:
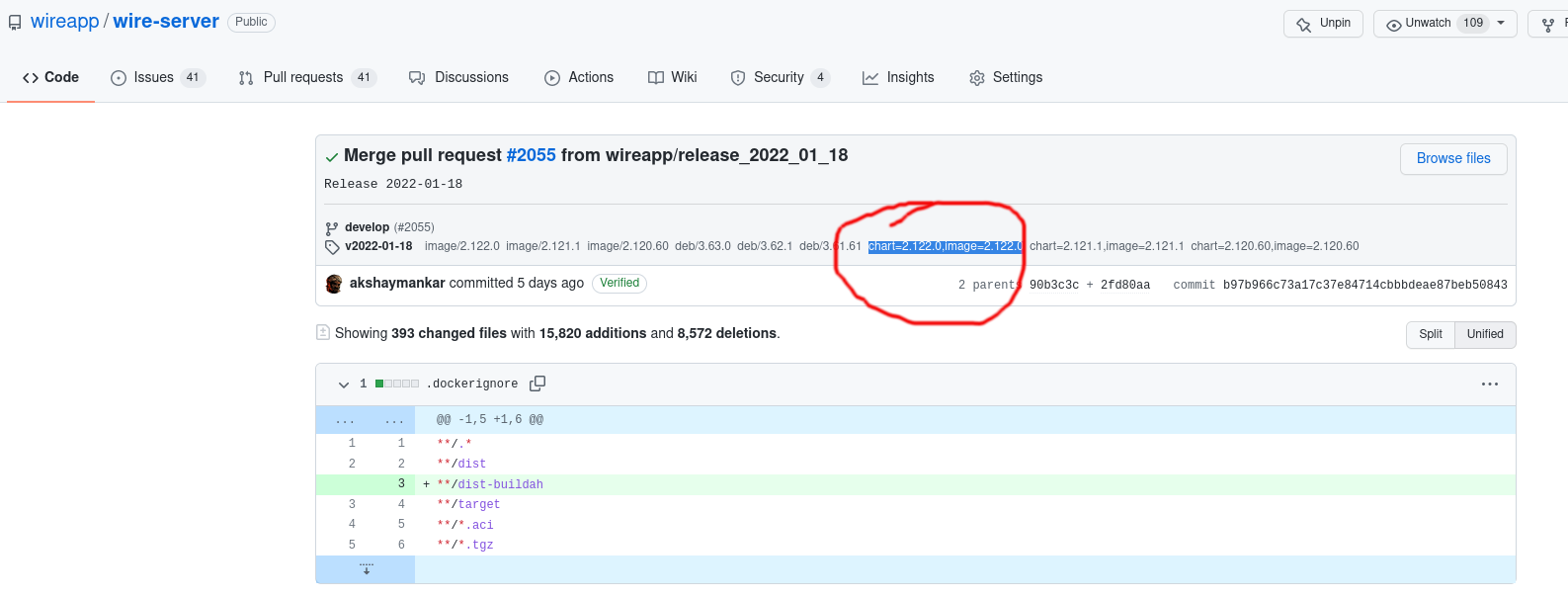
git tag --points-at chart=2.122.0,image=2.122.0 | sort
Note that the actual tag has the form chart=<release-tag>,image=<release-tag>.
Unfortunately, older releases may have more helm chart tags; you need to find the largest number that has the form N.NNN.0 from the list yourself.
A list of all releases can be produced like this:
git log --decorate --first-parent origin/master
If you want to find the
In the github UI
Consult the changelog to find the github tag of the release you’re interested in (say, v2022-01-18).
Visit the release notes of that release. Click on the commit hash:
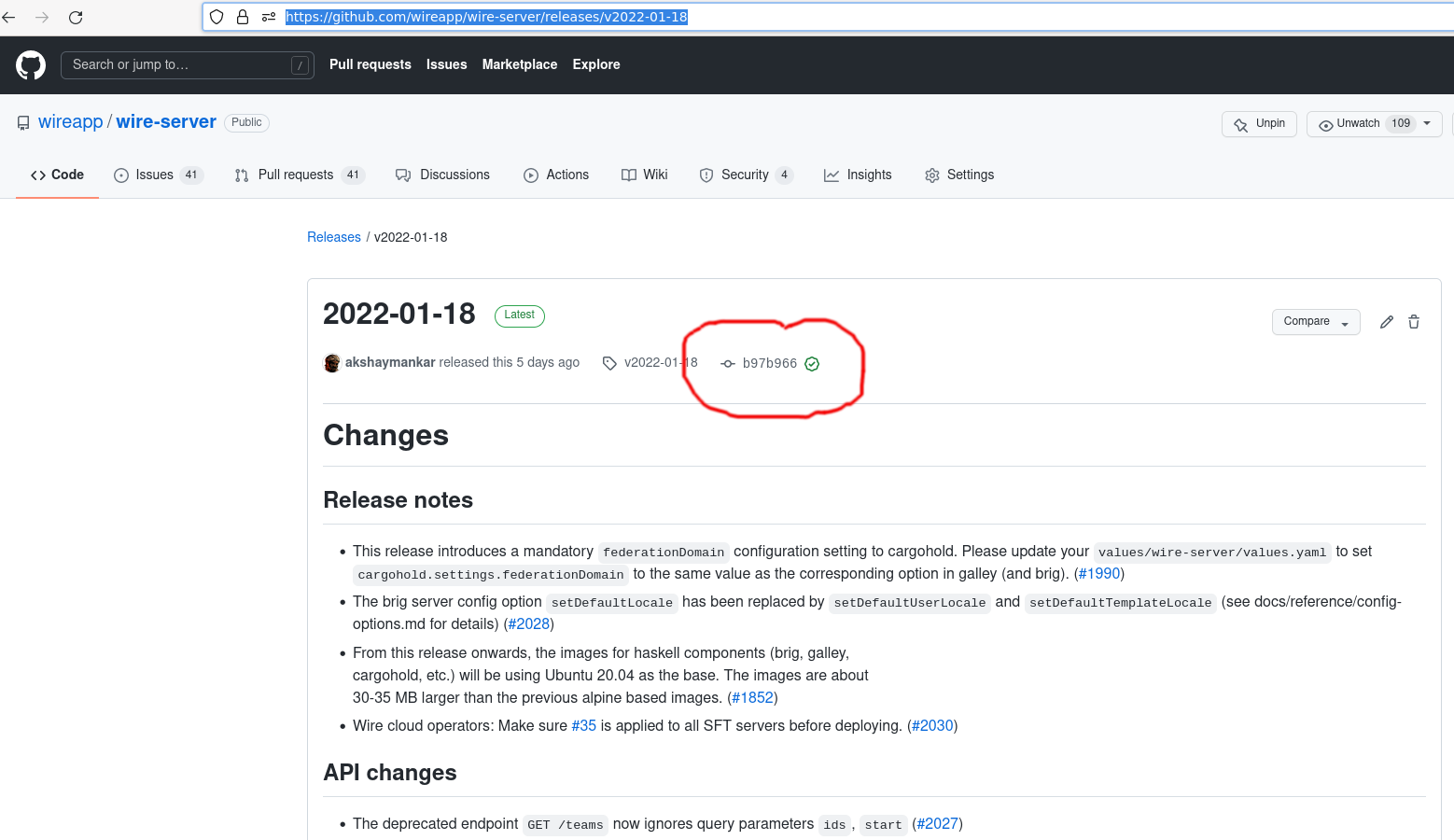
Click on the 3 dots:
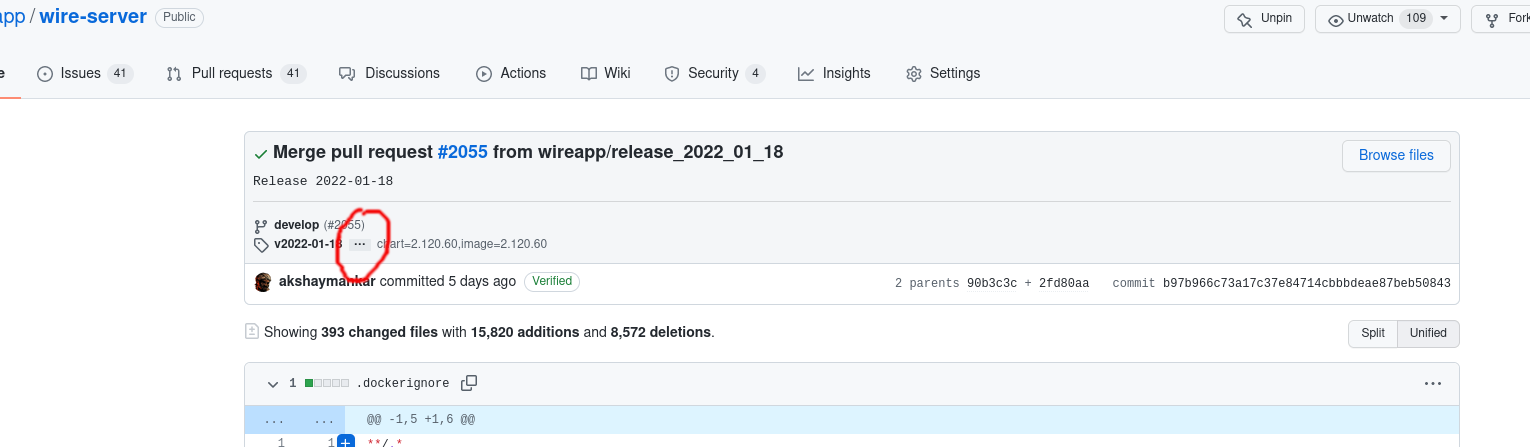
Now you can see a (possibly rather long) list of tags, some of then
have the form chart=N.NNN.0,image=N.NNN.0. Pick the one with the
largest number.